| province | full-time | part-time | unemployed |
|---|---|---|---|
| Newfoundland and Labrador | 205.0 | 39.3 | 27.3 |
| Prince Edward Island | 82.1 | 11.9 | 7.6 |
| Nova Scotia | 437.7 | 87.2 | 34.0 |
| New Brunswick | 346.8 | 54.8 | 30.0 |
| Quebec | 3762.6 | 864.7 | 279.6 |
| Ontario | 6721.8 | 1508.0 | 667.2 |
| Manitoba | 608.4 | 122.6 | 46.3 |
| Saskatchewan | 498.1 | 115.4 | 31.7 |
| Alberta | 2084.6 | 466.2 | 195.0 |
| British Columbia | 2357.1 | 587.8 | 190.1 |
Dimension
Analyse factorielle des correspondances
Steven Golovkine
03 oct. 2025
Limite de l’ACP
L’analyse en composantes principales est restreinte à des données quantitatives.
→ Comment faire lorsque l’on a des données qualitatives ?
Plan
La théorie de l’analyse factorielle des correspondances
L’AFC en pratique
Exemple : le taux d’emploi au Canada
Analyse factorielle des correspondances
L’Analyse Factorielle des Correspondances (AFC) est une méthode d’analyse exploratoire pour représenter graphiquement les relations entre les modalités de deux variables qualitatives.
Objectif → Trouver une représentation en faible dimension tout en gardant le maximum d’information possible.
Notation
Tableau de contingence:
\[K = (k_{ij}) \text{ avec } k_{ij} = \text{ effectif classe } i \in \{1, \dots, n\}, \text{ catégorie } j \in \{1, \dots, p\}.\]
Notation
Tableau de fréquences relatives :
\[F = (f_{ij}) \text{ où } f_{ij} = \frac{k_{ij}}{k_{\bullet\bullet}}.\]
Notation
Marges :
Ligne : \(f_{i\bullet} = \sum_{j=1}^p f_{ij}\)
Colonne : \(f_{\bullet j} = \sum_{i=1}^n f_{ij}\)
Total : \(f_{\bullet\bullet} = 1\)
Exemple concret
| Collège | Université Laval | Autre université | Hors Québec | \(f_{i \bullet}\) | |
|---|---|---|---|---|---|
| Actuariat | 0.08 | 0 | 0 | 0.04 | 0.12 |
| Statistique | 0.08 | 0.16 | 0.04 | 0 | 0.28 |
| Bio-info | 0.16 | 0.08 | 0 | 0.08 | 0.32 |
| Finance | 0.08 | 0 | 0 | 0 | 0.08 |
| Maths | 0.04 | 0 | 0 | 0 | 0.04 |
| Info | 0.08 | 0.04 | 0 | 0.04 | 0.16 |
| \(f_{\bullet j}\) | 0.52 | 0.28 | 0.04 | 0.16 | 1 |
Indépendance statistique
Test d’indépendance : Si les variables sont indépendantes, \[f_{ij} \approx f_{i\bullet} f_{\bullet j}\]
Indépendance statistique
Test du \(\chi^2\) :
\[T = \sum_{i,j} \frac{(k_{ij} - \mathbb{E}(k_{ij}))^2}{\mathbb{E}(k_{ij})} = \sum_{i,j} \frac{(k_{ij} - \frac{k_{i\bullet}k_{\bullet j}}{k_{\bullet\bullet}})^2}{\frac{k_{i\bullet}k_{\bullet j}}{k_{\bullet\bullet}}}\]
Si \(T \approx 0\) → indépendance
Si \(T\) grand → dépendance (intéressant pour l’AFC)
Profils-lignes et profils-colonnes
Profil-ligne \(i\) : Répartition de la modalité \(i\) parmi les colonnes \[L_i = \left(\frac{f_{i1}}{f_{i\bullet}}, \ldots, \frac{f_{ip}}{f_{i\bullet}}\right).\]
Profil-colonne \(j\) : Répartition de la modalité \(j\) parmi les lignes \[C_j = \left(\frac{f_{1j}}{f_{\bullet j}}, \ldots, \frac{f_{nj}}{f_{\bullet j}}\right).\]
Les profils sont des distributions conditionnelles.
Profils moyens
Profil-ligne moyen = fréquences marginales colonnes : \[\text{Profil moyen} = (f_{\bullet 1}, \ldots, f_{\bullet p})\]
Profil-colonne moyen = fréquences marginales lignes : \[\text{Profil moyen} = (f_{1\bullet}, \ldots, f_{n\bullet})\]
Indépendance \(\Longleftrightarrow\) Tous les profils \(\approx\) profils moyens.
Distance du \(\chi^2\)
Distance entre profils-lignes : \[d^2(L_i, L_{i'}) = \sum_{j=1}^p \frac{1}{f_{\bullet j}} \left(\frac{f_{ij}}{f_{i\bullet}} - \frac{f_{i'j}}{f_{i'\bullet}}\right)^2\]
Distance entre profils-colonnes : \[d^2(C_j, C_{j'}) = \sum_{i=1}^n \frac{1}{f_{i\bullet}} \left(\frac{f_{ij}}{f_{\bullet j}} - \frac{f_{ij'}}{f_{\bullet j'}}\right)^2\]
Formulation matricielle
Matrices de poids :
\(D_n = \text{diag}(f_{i\bullet})\) → poids des lignes
\(D_p = \text{diag}(f_{\bullet j})\) → poids des colonnes
Distance du \(\chi^2\) matricielle :
Profils-lignes : \(d^2(L_i, L_{i'}) = (L_i - L_{i'})^\top D_p^{-1} (L_i - L_{i'})\)
Profils-colonnes : \(d^2(C_j, C_{j'}) = (C_j - C_{j'})^\top D_n^{-1} (C_j - C_{j'})\)
Analyse directe (profils-lignes)
Objectif : Maximiser la variance projetée des profils-lignes
Problème d’optimisation : \[\max_u u^\top D_p^{-1} F^\top D_n^{-1} F D_p^{-1} u \quad \text{s.c.} \quad u^\top D_p^{-1} u = 1\]
Solution : Vecteurs propres de la matrice \[S = F^\top D_n^{-1} F D_p^{-1}\]
Premier axe factoriel : \(S u_1 = \lambda_1 u_1\)
Analyse duale (profils-colonnes)
Objectif : Maximiser la variance projetée des profils-colonnes
Problème d’optimisation similaire avec matrice : \[T = F D_p^{-1} F^\top D_n^{-1}\]
Premier axe factoriel : \(T v_1 = \mu_1 v_1\)
Propriété
Propriété
\(S\) et \(T\) ont les mêmes \(r = \min(n-1, p-1)\) valeurs propres positives !
Relations entre analyses
Cohérence des représentations : \(\lambda_k = \mu_k\) pour \(k = 1, \ldots, r\)
Relations entre vecteurs propres : \[u_k = \frac{1}{\sqrt{\lambda_k}} F^\top D_n^{-1} v_k.\] \[v_k = \frac{1}{\sqrt{\lambda_k}} F D_p^{-1} u_k.\]
Cette propriété garantit une représentation cohérente dans le même espace réduit.
AFC comme double ACP
Remarque
L’AFC peut être vue comme une double ACP pondérée :
ACP des profils-lignes dans \(\mathbb{R}^p\),
ACP des profils-colonnes dans \(\mathbb{R}^n\),
Avec métriques du \(\chi^2\) adaptées à chaque espace.
Coordonnées factorielles
Coordonnées des profils-lignes sur l’axe \(k\) :
\[\Phi_k = D_n^{-1} F D_p^{-1} u_k.\]
Coordonnées des profils-colonnes sur l’axe \(k\) :
\[\Psi_k = D_p^{-1} F^\top D_n^{-1} v_k.\]
Relations entre coordonnées : \[\Phi_k = \frac{1}{\sqrt{\lambda_k}} D_n^{-1} F \Psi_k.\]
Centrage et centre de gravité
Convention : Représentation centrée en \((0,0)\) dans les logiciels.
Centres de gravité :
Lignes : \(G_L = (f_{\bullet 1}, \ldots, f_{\bullet p})^\top\).
Colonnes : \(G_C = (f_{1\bullet}, \ldots, f_{n\bullet})^\top\).
Centrage : Soustraire les profils moyens
\[\frac{f_{ij}}{f_{i\bullet}} - f_{\bullet j} = \frac{f_{ij} - f_{i\bullet}f_{\bullet j}}{f_{i\bullet}}.\]
AFC sur matrice centrée
Matrice centrée : \(S^* = (s_{jj'}^*)\) avec
\[s_{jj'}^* = \sum_{i=1}^n \frac{(f_{ij} - f_{i\bullet}f_{\bullet j})(f_{ij'} - f_{i\bullet}f_{\bullet j'})}{f_{i\bullet}f_{\bullet j'}}.\]
Inertie totale
Inertie totale :
\[\text{tr}(S^*) = \sum_{j=1}^p \sum_{i=1}^n \frac{(f_{ij} - f_{i\bullet}f_{\bullet j})^2}{f_{i\bullet}f_{\bullet j}}\]
Cette inertie correspond à la statistique du \(\chi^2\) normalisée.
Représentation barycentrique
Sur chaque axe factoriel,
\[[\Phi_k]_i = \frac{1}{\sqrt{\lambda_k}} \sum_{j=1}^p \frac{f_{ij}}{f_{i\bullet}} [\Psi_k]_j,\]
\[[\Psi_k]_j = \frac{1}{\sqrt{\lambda_k}} \sum_{i=1}^n \frac{f_{ij}}{f_{\bullet j}} [\Phi_k]_i.\]
Interprétation : Chaque profil-ligne est au barycentre des profils-colonnes (et vice versa).
Double représentation barycentrique
Propriété fondamentale de l’AFC :
Sur les axes factoriels, chaque point d’un nuage est au barycentre des points de l’autre nuage, pondéré par les contributions respectives.
Cette propriété permet une interprétation conjointe des modalités des deux variables dans le même graphique.
Interprétation des résultats
Proximité géométrique = Similarité des profils
Axes factoriels : Directions de variation maximale.
Contribution des modalités : Importance dans la construction des axes.
Qualité de représentation : Proportion de l’inertie d’un point expliquée par les axes retenus.
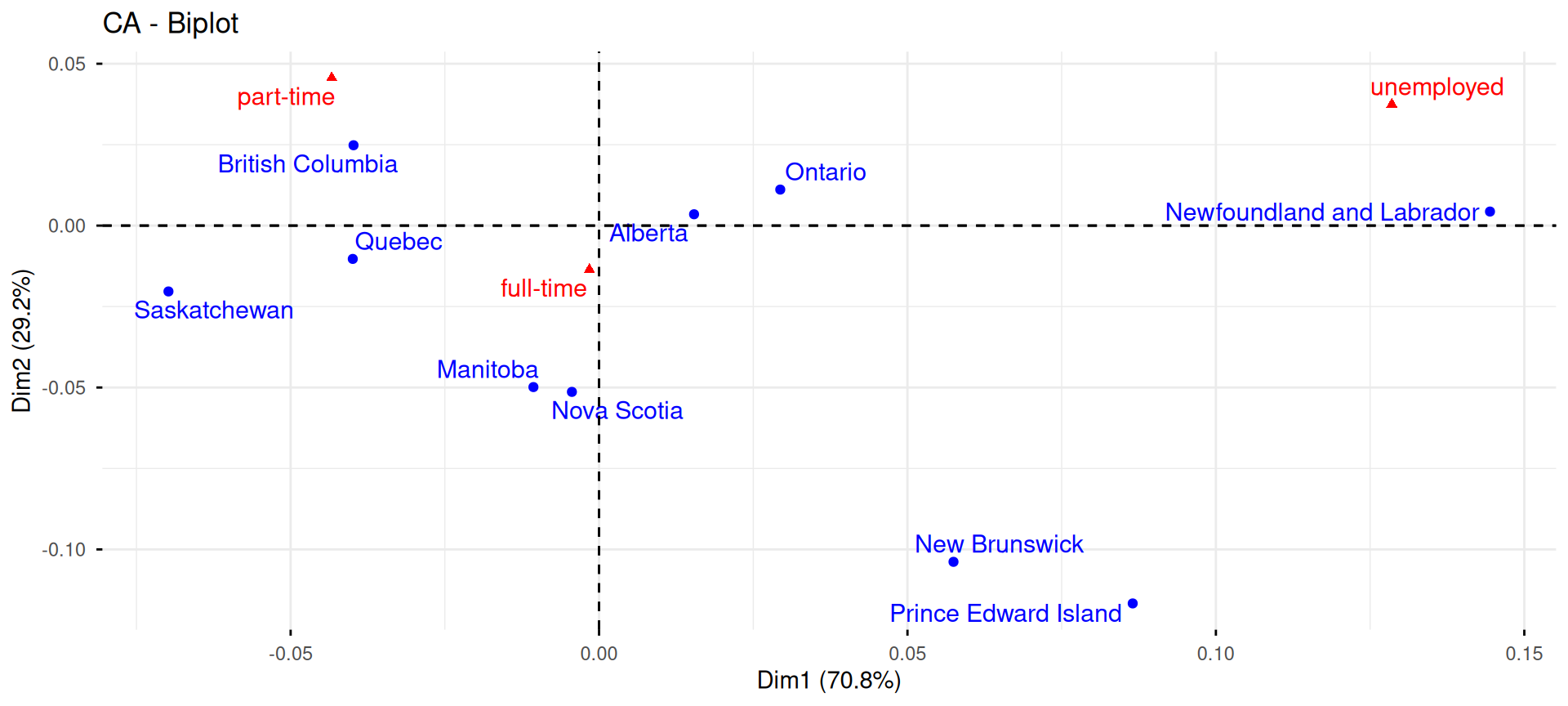
Exemple : le taux d’emploi au Canada
On considère le jeu de données suivant :
Exemple : le taux d’emploi au Canada
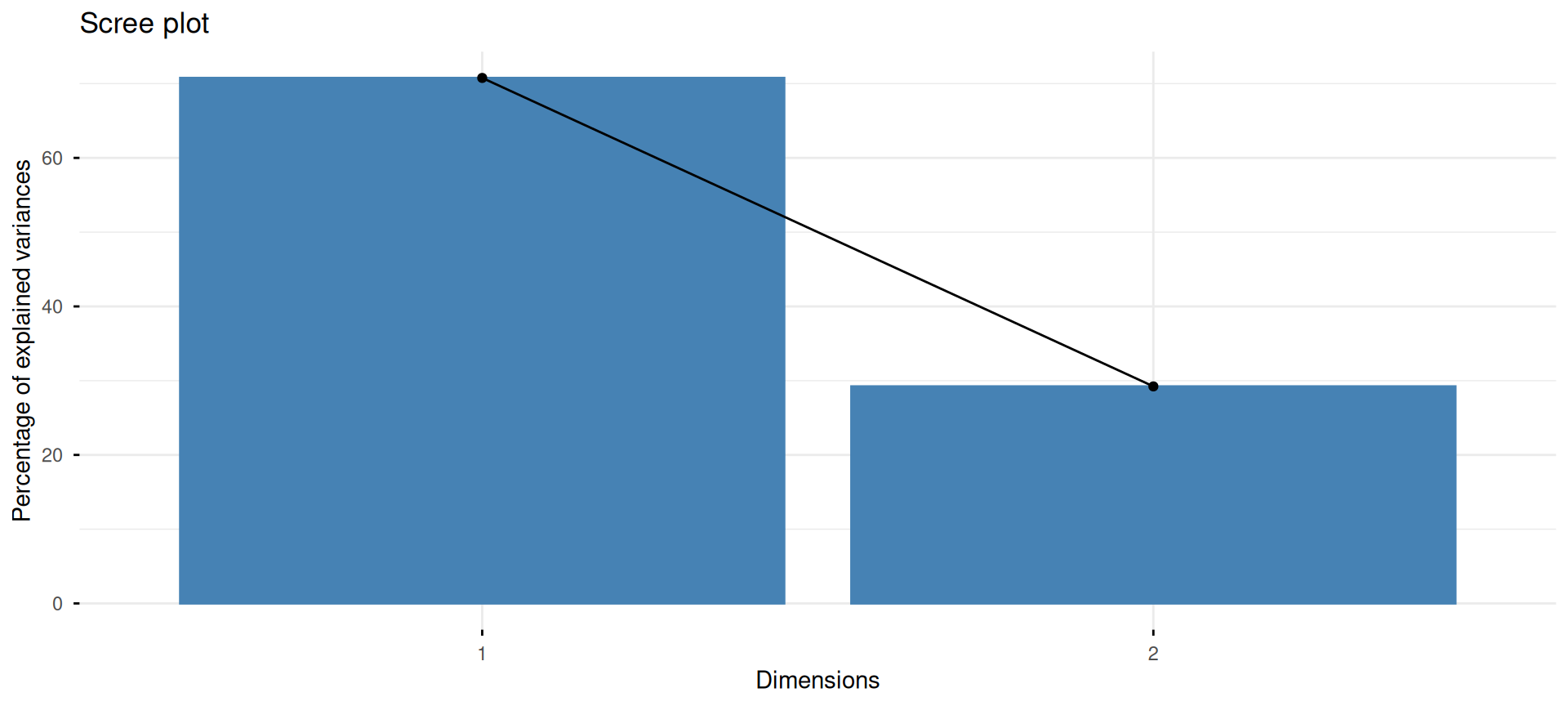
Exemple : le taux d’emploi au Canada
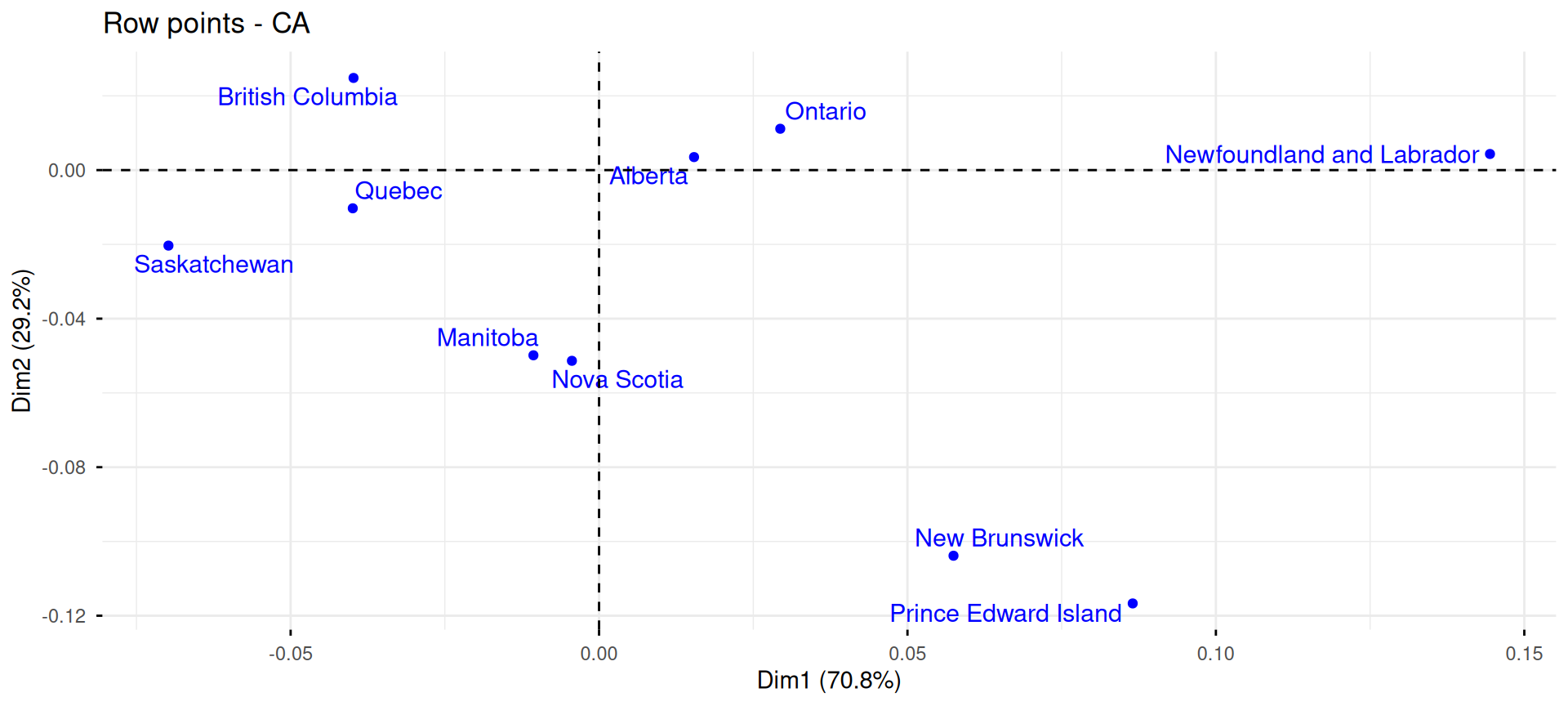
Exemple : le taux d’emploi au Canada
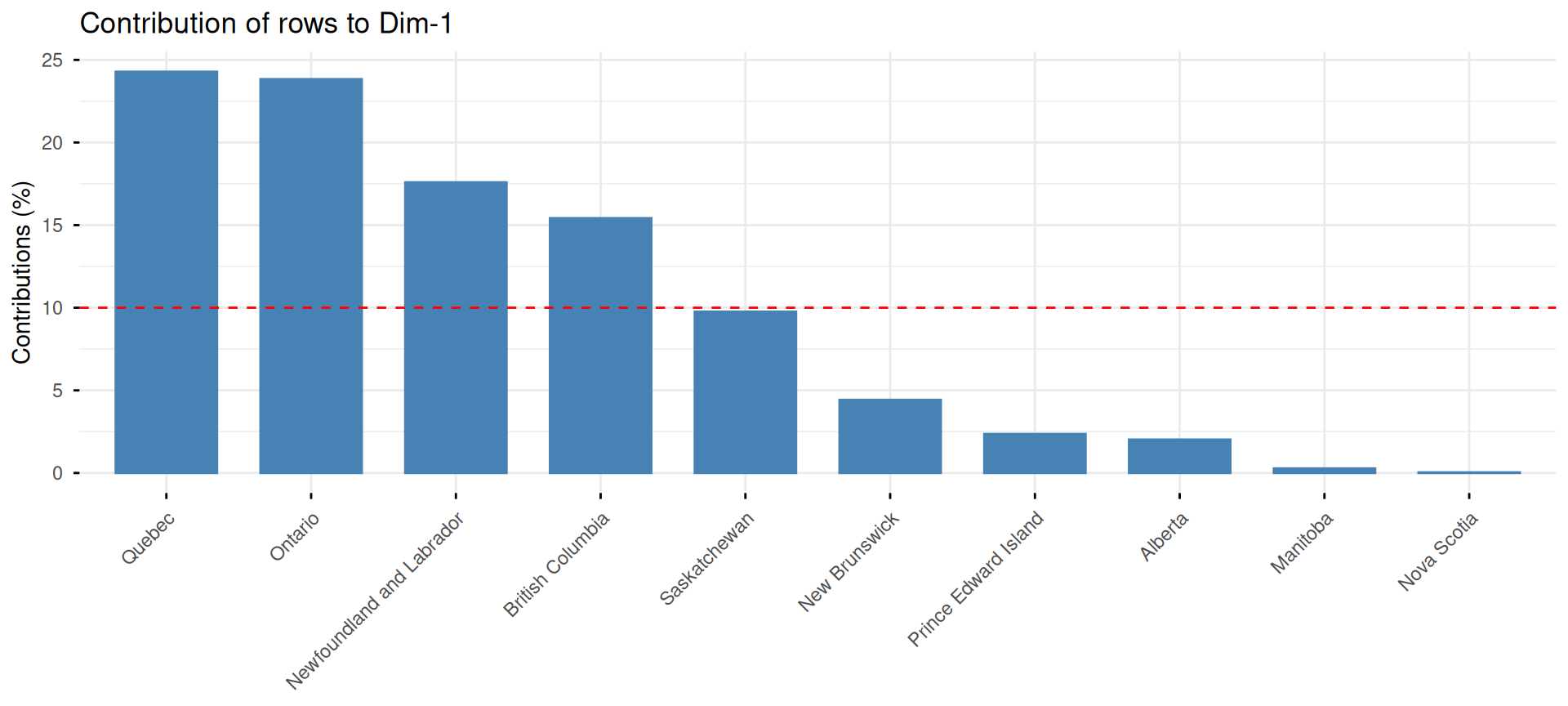
Exemple : le taux d’emploi au Canada
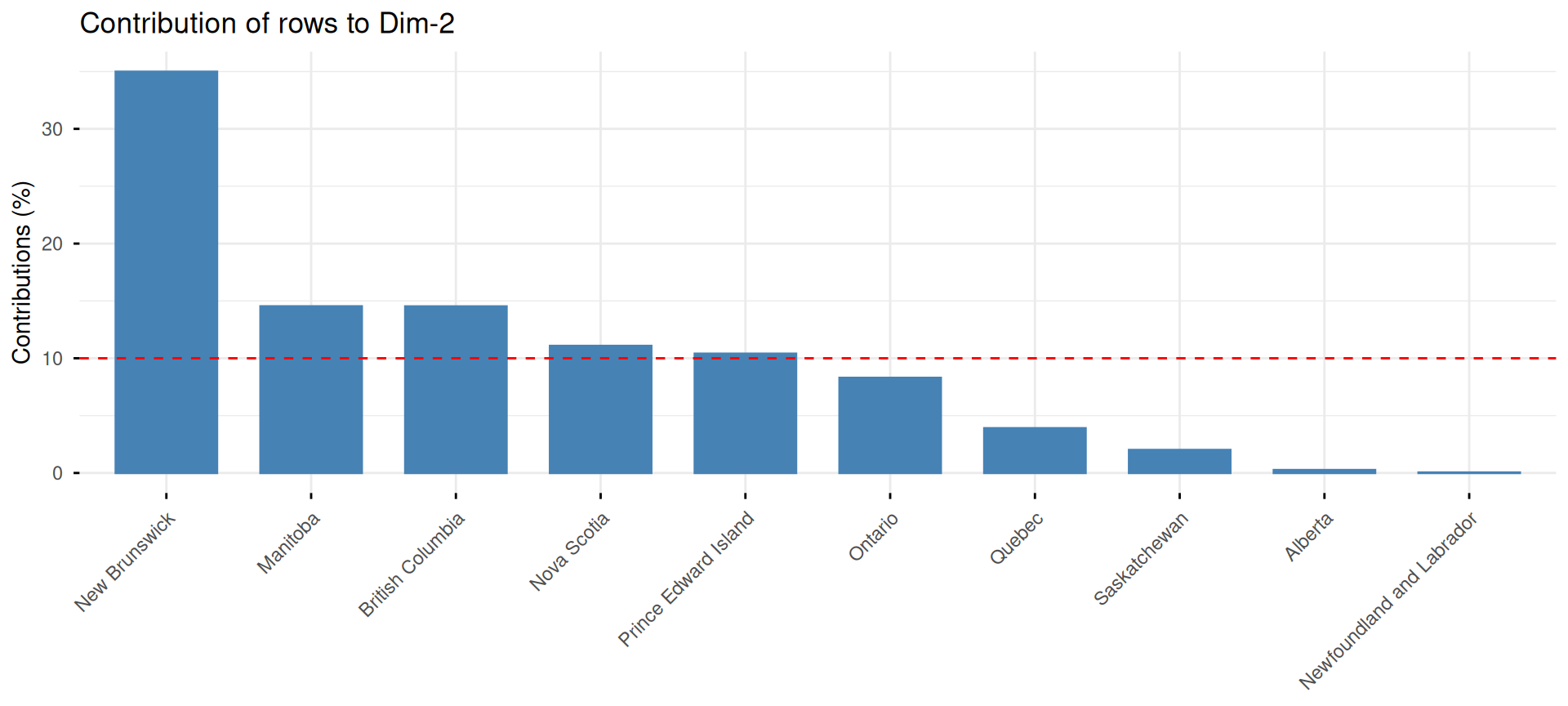
Exemple : le taux d’emploi au Canada
Conclusion
L’AFC est un outil pour :
Explorer les relations entre variables qualitatives
Visualiser des structures complexes en 2D/3D
Identifier des associations non évidentes
Interpréter conjointement lignes et colonnes
Prochaine étape → Que faire si on a plus que deux variables qualitatives ?