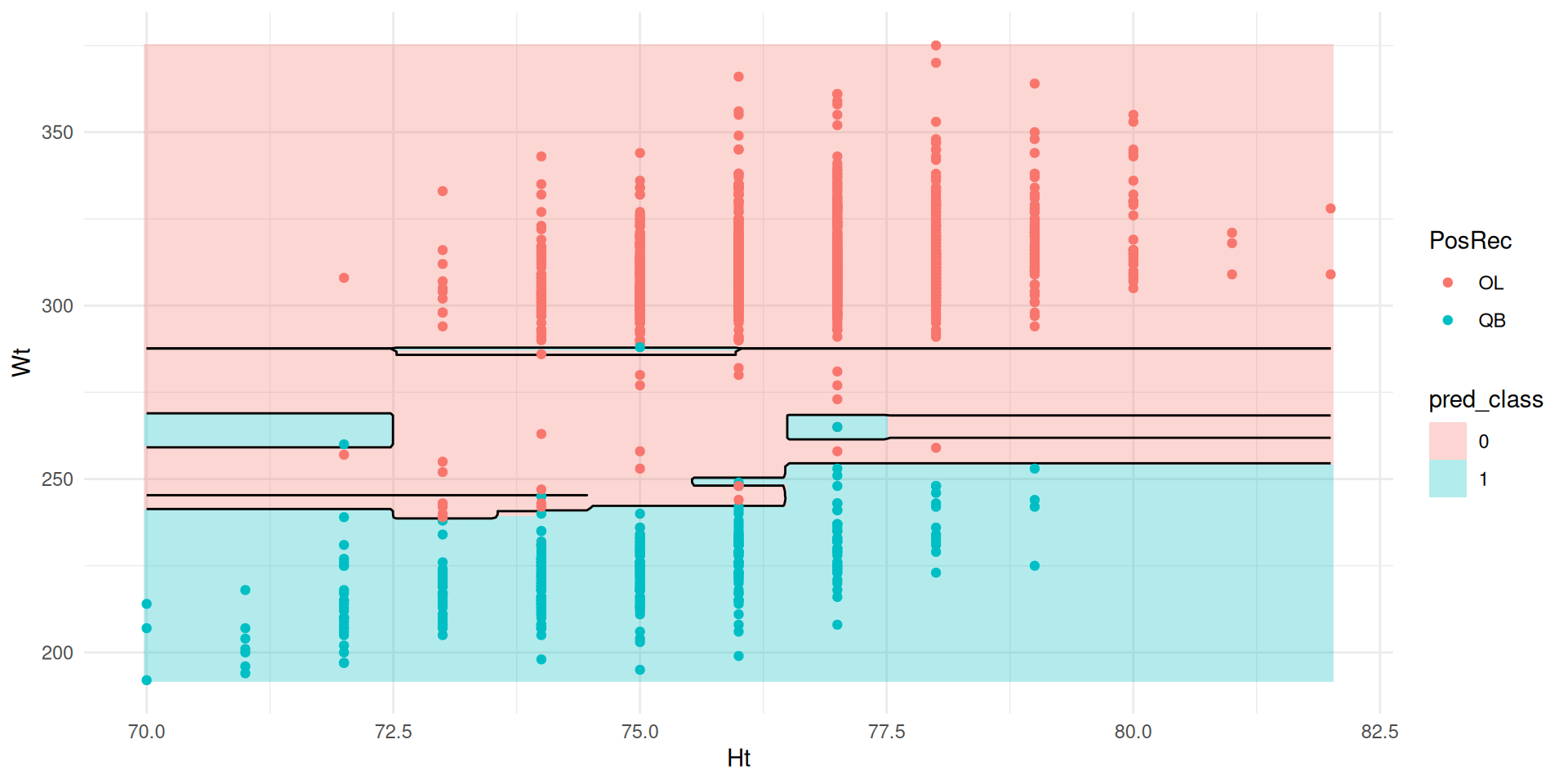
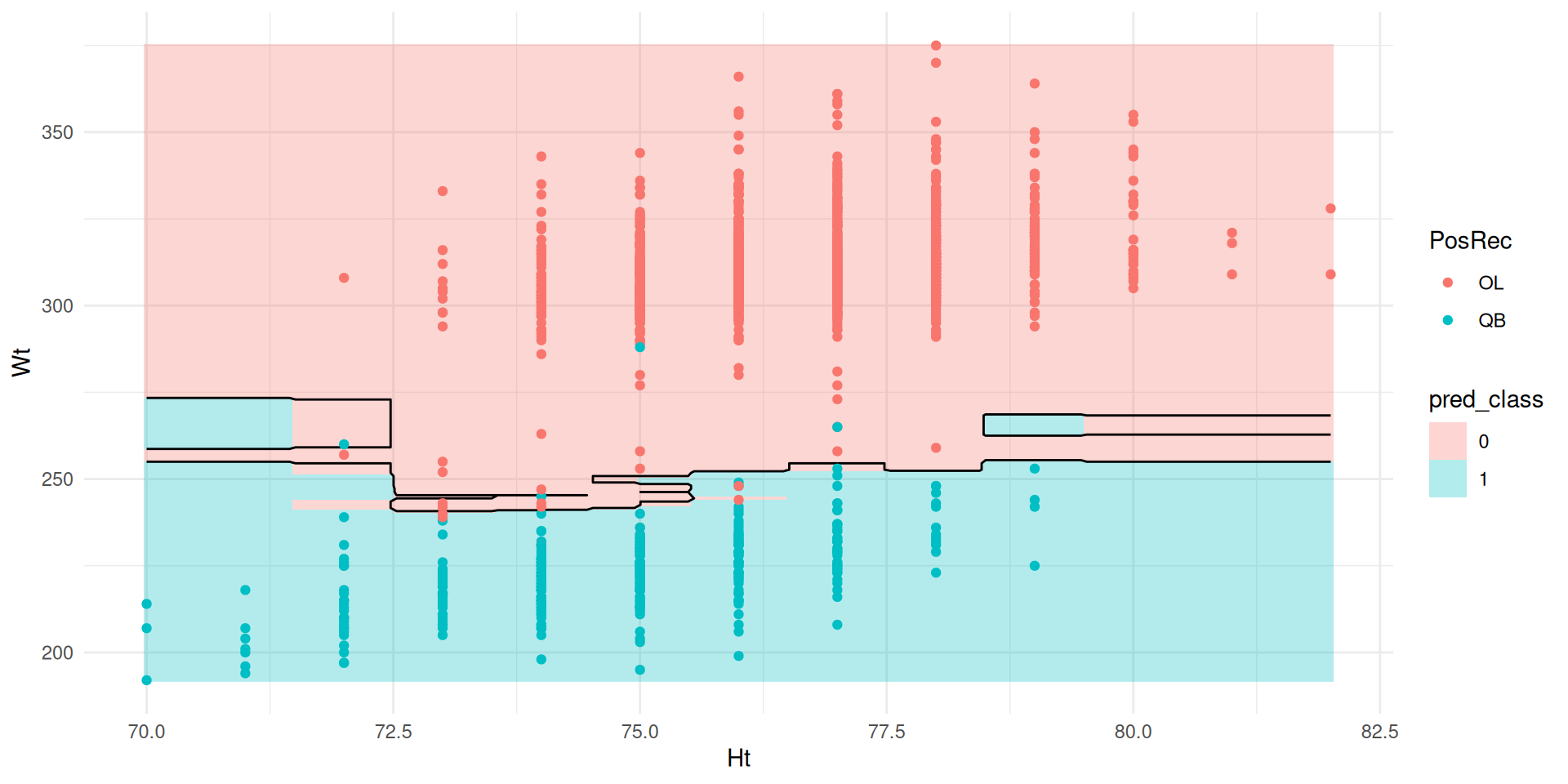
Supposons que pour un exercice de classification binaire pour une observation, trois méthodes me donnent respectivement des probabilités \(0.3\), \(0.505\) et \(0.515\) que cette observation soit “positive” (et donc des probabilités \(0.7\), \(0.495\) et \(0.485\) que cette observation soit “négative”).
Moyenne des probabilités : \((0.3 + 0.505 + 0.515) / 3 = 0.44 < 0.5\), donc on prédit “négatif”.
Vote de majorité: deux méthodes prédisent “positif” et une prédit “négatif”, donc on prédit “positif”.
Remarque: on peut pondérer les moyennes ou les votes !
Bagging (Bootstrap Aggregating)
Construire plusieurs versions d’un même modèle sur des échantillons différents.
Algorithme :
Générer \(B\) échantillons bootstrap (tirage avec remise).
Obtenir \(B\) arbres de classification (ou autre).
Prédire par vote de majorité ou moyenne des probabilités.
Bootstrap
Le bootstrap est une technique basée sur l’échantillonage aléatoire, ce qui permet d’estimer la distribution (échantillonale) de (presque) toutes les statistiques.
Avantages et inconvénients
Réduction de la variance des prédictions
Augmentation de la stabilité des prédictions
Perte d’interprétabilité des variables individuelles
Un bagging d’un bon classificateur peut le rendre meilleur, un bagging d’un mauvais classificateur peut le rendre moins bon.
Évaluation de l’importance des variables
Sommer les réductions d’indice de Gini par variable.