Supervisée
Arbres de décision
07 nov. 2025
Exemple
n= 400
node), split, n, deviance, yval
* denotes terminal node
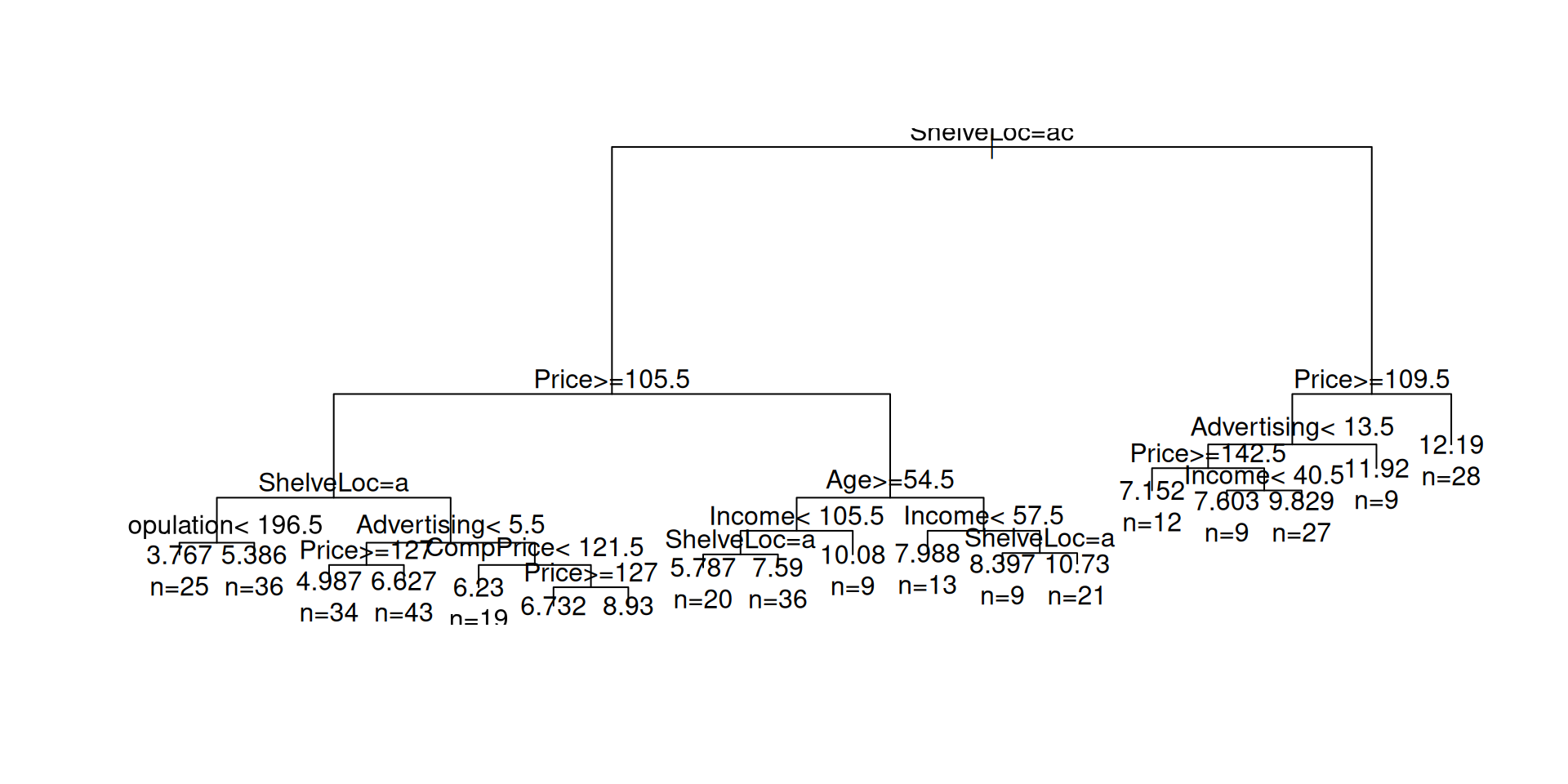
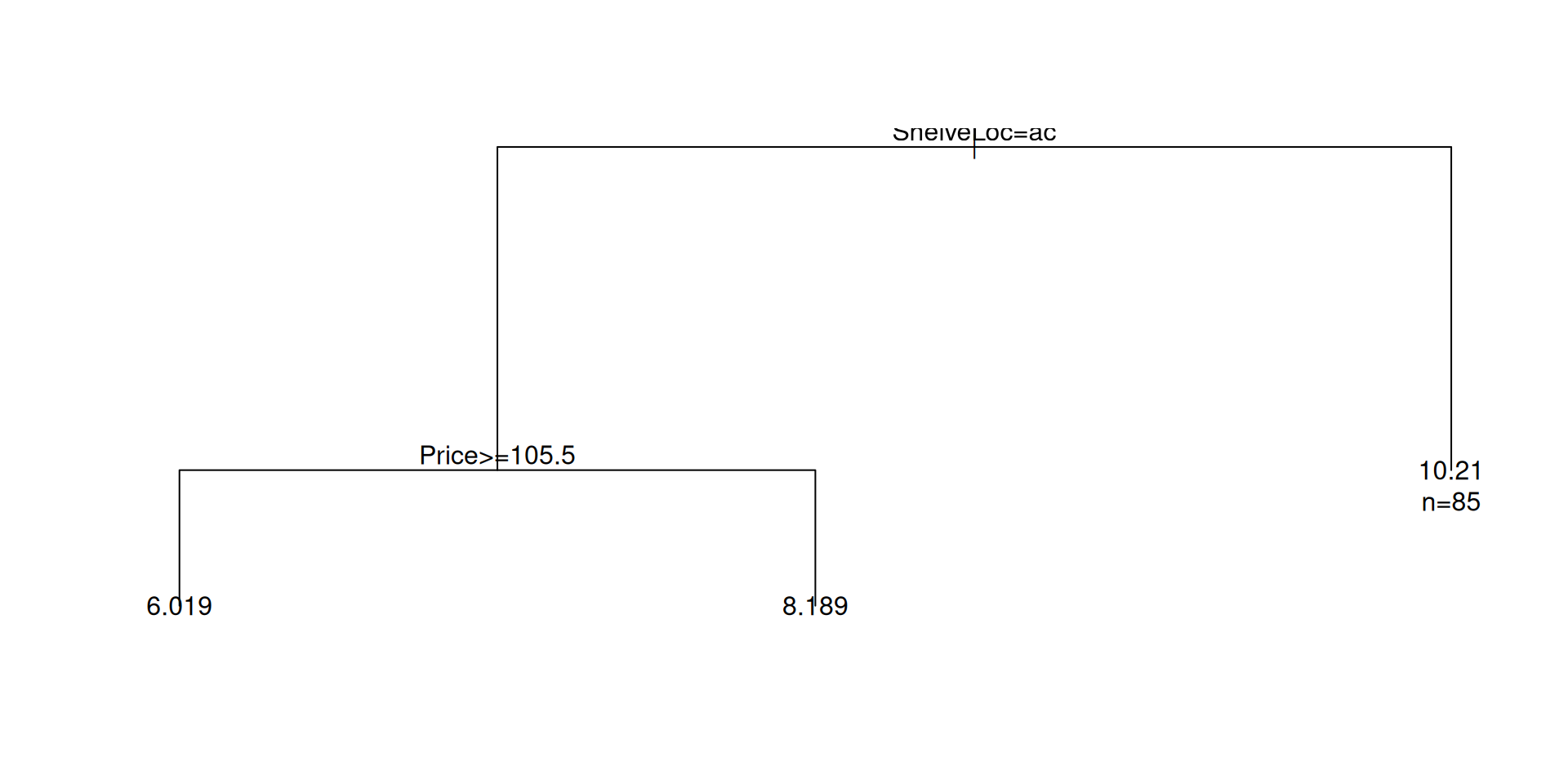
1) root 400 3182.27500 7.496325
2) ShelveLoc=Bad,Medium 315 1859.56000 6.762984
4) Price>=105.5 207 956.57240 6.018792
8) ShelveLoc=Bad 61 240.81970 4.722459
16) Population< 196.5 25 88.22930 3.767200 *
17) Population>=196.5 36 113.93510 5.385833 *
9) ShelveLoc=Medium 146 570.41420 6.560411
18) Advertising< 5.5 77 280.11340 5.902468
36) Price>=127 34 133.53970 4.986765 *
37) Price< 127 43 95.52198 6.626512 *
19) Advertising>=5.5 69 219.77110 7.294638
38) CompPrice< 121.5 19 40.33360 6.230000 *
39) CompPrice>=121.5 50 149.71840 7.699200
78) Price>=127 28 71.99441 6.731786 *
79) Price< 127 22 18.16730 8.930455 *
5) Price< 105.5 108 568.61750 8.189352
10) Age>=54.5 65 303.05690 7.380154
20) Income< 105.5 56 203.03290 6.946071
40) ShelveLoc=Bad 20 76.96006 5.786500 *
41) ShelveLoc=Medium 36 84.24070 7.590278 *
21) Income>=105.5 9 23.81549 10.081110 *
11) Age< 54.5 43 158.66040 9.412558
22) Income< 57.5 13 19.24283 7.987692 *
23) Income>=57.5 30 101.58740 10.030000
46) ShelveLoc=Bad 9 22.75640 8.396667 *
47) ShelveLoc=Medium 21 44.53100 10.730000 *
3) ShelveLoc=Good 85 525.52220 10.214000
6) Price>=109.5 57 277.26520 9.244386
12) Advertising< 13.5 48 185.42030 8.742500
24) Price>=142.5 12 36.64722 7.152500 *
25) Price< 142.5 36 108.32350 9.272500
50) Income< 40.5 9 9.82780 7.603333 *
51) Income>=40.5 27 65.06227 9.828889 *
13) Advertising>=13.5 9 15.27049 11.921110 *
7) Price< 109.5 28 85.57727 12.187860 *