Non-supervisée
Mélange de gaussiennes
28 nov. 2025
Qu’est-ce qu’un mélange de gaussiennes ?
Idée centrale : Les données proviennent de plusieurs sous-populations (clusters), chacune suivant une distribution normale.
Objectif :
Identifier les clusters
Estimer les paramètres de chaque distribution
Assigner les observations aux clusters
Plan
Hypothèses du modèle
Vraisemblance
Contraintes sur covariances
Sélection de \(K\)
Exemple
Hypothèses du modèle
Données : \((X_1, \ldots, X_n)\) observations
Structure :
\(K\) sous-populations (clusters).
\(C(i) \in \{1, \ldots, K\}\) : étiquette (non observée) de l’observation \(i\).
Chaque cluster \(k\) caractérisé par paramètre \(\theta_k\).
⚠️ Étiquettes \(C(i)\) inconnues !
Paramètres à estimer
Pour chaque cluster \(k \in \{1, \ldots, K\}\) :
\(\pi_k\) : Proportion (poids) du cluster
\(\theta_k\) : Vecteur des paramètres
Challenge : Estimation conjointe des paramètres ET des affectations.
Vraisemblance complète
Si on connaissait les étiquettes \(C\) :
\[L(\theta, C) = \prod_{k=1}^K \prod_{\{i : C(i)=k\}} f(X_i \mid \theta_k)\]
où \(f(\cdot \mid \theta_k)\) est la densité du cluster \(k\)
Problème : Les \(C(i)\) sont inconnus !
Cas gaussien : Vraisemblance complète
Hypothèse : Chaque cluster suit \(\mathcal{N}(\mu_k, \Sigma_k)\)
\[L(\theta, C) = \prod_{k=1}^{K} \prod_{i : C(i)=k} \frac{(2\pi)^{-d/2}}{\lvert \Sigma_k \rvert^{1/2}} \exp\left(-\frac{1}{2}(X_i - \mu_k)^\top \Sigma_k^{-1}(X_i - \mu_k)\right)\]
où \(d\) est la dimension des données
Vraisemblance marginale
Solution : Marginaliser sur les étiquettes inconnues
\[L(\theta) = \prod_{i=1}^n \left( \sum_{k=1}^K \pi_k \, f(X_i \mid \theta_k) \right)\]
Interprétation :
\(\pi_k = \mathbb{P}(C(i)=k)\) : probabilité a priori d’appartenance au cluster \(k\)
Pour chaque observation : somme pondérée des densités
Log-vraisemblance
En pratique, on maximise le log de la vraisemblance :
\[\log L(\theta) = \sum_{i=1}^n \log\left( \sum_{k=1}^K \pi_k \, f(X_i \mid \theta_k) \right)\]
Problème : Log d’une somme → pas de solution analytique simple.
Solution : Algorithme EM !
Algorithme EM : Vue d’ensemble
Itération entre deux étapes :
E-step : Estimer probabilités d’appartenance (avec paramètres courants).
M-step : Mettre à jour les paramètres (avec probabilités courantes).
Convergence vers un maximum local de la vraisemblance.
Contraintes sur les covariances: sphériques, même taille
\[\Sigma_k = \sigma^2 I\]
Caractéristiques :
Clusters = boules de même rayon
Comportement proche du \(k\)-means
Très contraint, peu de paramètres
Contraintes sur les covariances: sphériques, taille différente
\[\Sigma_k = \sigma_k^2 I\]
Caractéristiques :
Clusters sphériques
Dispersion différente par cluster
Plus flexible que cas précédent
Contraintes sur les covariances: diagonales
\[\Sigma_k = \text{diag}(\sigma_{k1}^2, \ldots, \sigma_{kd}^2)\]
Caractéristiques :
Dimensions supposées indépendantes
Ellipsoïdes alignés avec les axes
Standardisation préalable recommandée
Covariances générales (non contraintes)
\[\Sigma_k \text{ quelconque (définie positive)}\]
Caractéristiques :
Maximum de flexibilité
Ellipsoïdes de forme complètement libre
⚠️ Risque de sur-ajustement si \(d\) grand
Choix du nombre de clusters \(K\)
Problème : \(K\) n’est pas estimé par EM.
Stratégie :
Ajuster des modèles pour différentes valeurs de \(K\).
Comparer les modèles avec des critères pénalisés.
Sélectionner le meilleur modèle.
Exemple
----------------------------------------------------
Gaussian finite mixture model fitted by EM algorithm
----------------------------------------------------
Mclust EEE (ellipsoidal, equal volume, shape and orientation) model with 3
components:
log-likelihood n df BIC ICL
-131.2888 23 116 -626.2949 -626.2949
Clustering table:
1 2 3
4 4 15 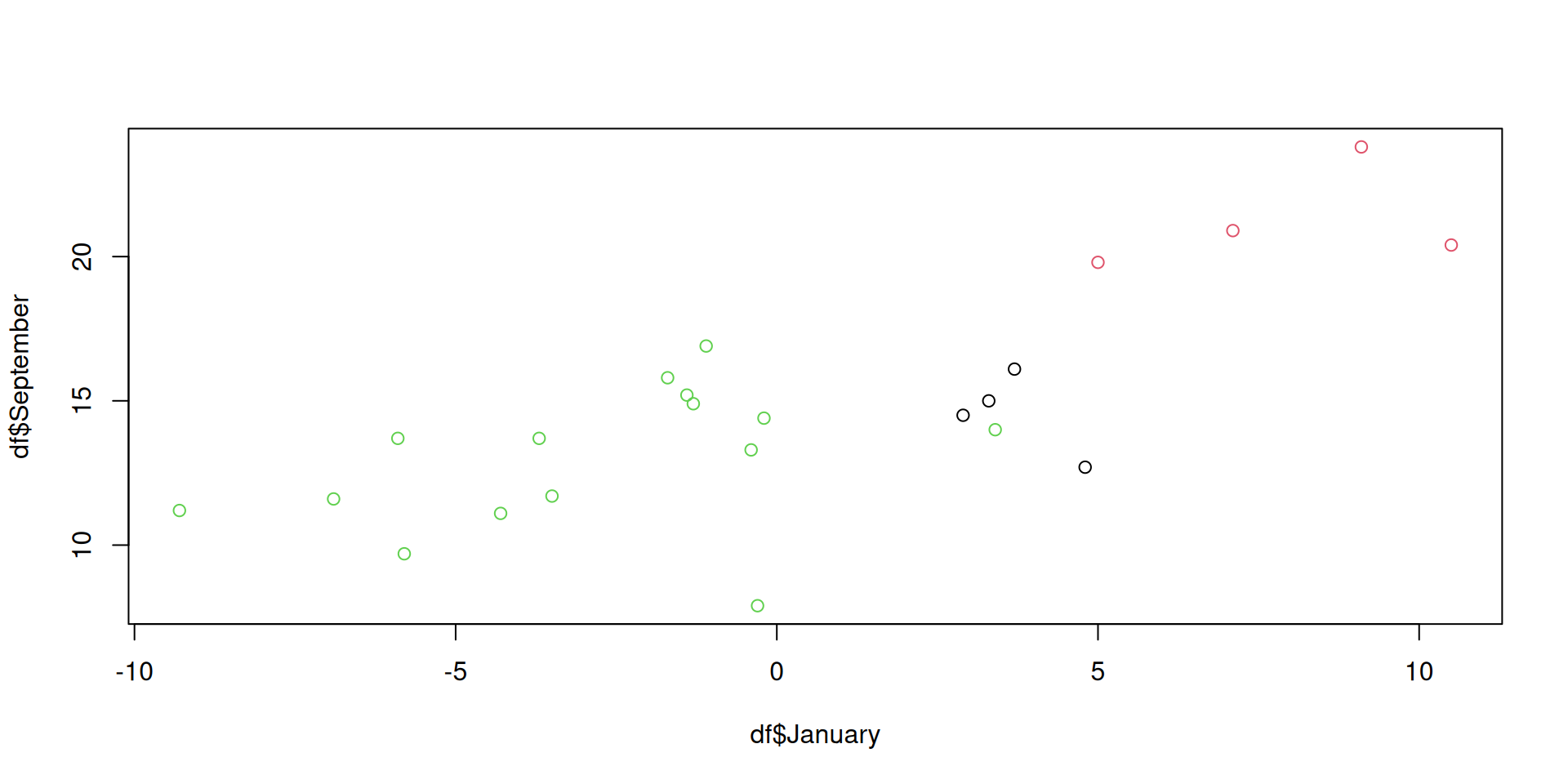
Avantages des mélanges gaussiens
Probabiliste : Incertitude sur affectations.
Flexible : Clusters de formes variées.
Théorique : Cadre mathématique solide.
Généralisable : Facilite la prédiction.
Modèle génératif : Peut simuler nouvelles données.
Limitations
Hypothèse gaussienne : Peut être restrictive.
Sensibilité à l’initialisation : Maxima locaux.
Choix de contraintes : Impact sur résultats.
Grande dimension : Difficultés si \(d\) grand.
Récapitulatif
Modèle probabiliste pour clustering
Algorithme EM : E-step (responsabilités) + M-step (paramètres)
Contraintes sur \(\Sigma_k\) → forme des clusters.
Prochaine étape → The END