Non-supervisée
Classification hiérarchique
21 nov. 2025
Plan
Généralités
Classifications ascendante et descendante
Méthodes d’aggrégation
En pratique : choix du nombre de groupes, cohérence de la partition
Exemple
Motivation
Série de partitions imbriquées
De \(n\) groupes (chaque observation isolée) à 1 groupe (toutes les observations ensemble)
Représentation : Dendrogramme
Types d’algorithmes
Algorithmes ascendants
Départ : \(n\) groupes individuels
Processus : Fusions successives
Algorithmes descendants
Départ : 1 groupe avec toutes les observations
Processus : Divisions successives
Résultat commun : \(n\) partitions hiérarchiques de 1 à \(n\) groupes.
Algorithmes descendants
Démarrage avec toutes les observations dans un groupe.
Division du groupe le moins homogène à chaque étape.
Maximisation de la dissimilarité entre sous-groupes.
Inconvénient majeur : Coût computationnel très élevé (évaluation de toutes les divisions possibles).
Algorithmes ascendants
Démarrage avec \(n\) groupes distincts.
Fusion des deux groupes les plus similaires à chaque étape.
Continuation jusqu’à un seul groupe.
Avantage : Plus efficace computationnellement que le descendant.
Enjeu clé dans les deux cas : Définir la distance entre groupes.
Distance du plus proche voisin (Single Linkage)
Distance = plus petite distance entre individus des deux groupes.
\[d(A, B) = \min \{d_{ij}: i \in A, j \in B\}\]
Distance du plus proche voisin (Single Linkage)
Avantages :
Bon avec des variables de types différents.
Groupes de formes irrégulières.
Robuste aux données aberrantes.
Bonnes propriétés théoriques.
Inconvénients :
Groupes déséquilibrés.
Moins performant pour groupes de forme régulière.
Distance du voisin le plus distant (Complete Linkage)
Distance = plus grande distance entre individus des deux groupes.
\[d(A, B) = \max \{d_{ij}: i \in A, j \in B\}\]
Distance du voisin le plus distant (Complete Linkage)
Avantages :
Groupes réguliers et homogènes en taille.
Adapté aux variables de types différents.
Inconvénients :
Extrêmement sensible aux données aberrantes.
Force des groupes de même taille.
Distance de la moyenne (Average Linkage)
Distance = moyenne de toutes les distances inter-groupes.
\[d(A, B) = \frac{1}{n_A n_B} \sum_{i \in A} \sum_{j \in B} d(X_i, X_j)\]
Distance de la moyenne (Average Linkage)
Avantages :
Considère toutes les interactions.
Produit des groupes homogènes (variance faible).
Inconvénients :
Privilégie des groupes de variance similaire.
Moins performant pour groupes de forme irrégulière.
Méthode du centroïde
Distance entre les moyennes des groupes.
\[d(A, B) = d(\overline{X}_A, \overline{X}_B)\]
Mise à jour après fusion :
\[\overline{X}_{AB} = \frac{n_A \overline{X}_A + n_B \overline{X}_B}{n_A + n_B}\]
→ Assez robuste aux données aberrantes, mais peu performant sans elles.
Distance de la médiane
Principe : Mise à jour récursive des distances.
Formule de mise à jour :
\[d(AB, C) = \frac{d(A, C) + d(B, C)}{2} - \frac{d(A, B)}{4}\]
Caractéristiques :
Très robuste aux données aberrantes.
Peu efficace sans valeurs extrêmes.
Méthode de Ward
Principe : Minimisation de l’augmentation d’inertie intra-groupe.
\[SC_A = \sum_{i \in A} (X_i - \overline{X}_A)^\top (X_i - \overline{X}_A),\]
\[SC_B = \sum_{j \in B} (X_j - \overline{X}_B)^\top (X_j - \overline{X}_B),\]
\[SC_{AB} = \sum_{k \in A \cup B} (X_k - \overline{X}_{AB})^\top (X_k - \overline{X}_{AB}).\]
Méthode de Ward
Critère d’optimisation : \[I_{AB} = SC_{AB} - SC_A - SC_B = \frac{d^2(\overline{X}_A, \overline{X}_B)}{\frac{1}{n_A} + \frac{1}{n_B}}\]
Conditions optimales :
Observations gaussiennes multivariées.
Même matrice de variance-covariance.
Moyennes différentes.
Méthode de Ward
Avantages :
Très efficace sous hypothèses gaussiennes.
Groupes homogènes et de taille comparable.
Méthode très populaire en pratique.
Inconvénients :
Sensible aux données aberrantes.
Tend à former des groupes de même taille.
Hypothèses gaussiennes restrictives.
Distance flexible
\[\begin{align} d(C, AB) &= \alpha_A d(C, A) \\ &~ + \alpha_B d(C, B) \\ &~ + \beta d(A, B) \\ &~ + \gamma |d(C, A) - d(C, B)| \end{align}\]
Selon \((\alpha_A, \alpha_B, \beta, \gamma)\), on retrouve toutes les méthodes précédentes.
Paramétrage standard :
\(\alpha_A = \alpha_B\), \(\alpha_A + \alpha_B + \beta = 1\), \(\gamma = 0\)
Choix courant : \(\beta = -0.25\) (\(\beta = -0.5\) si données aberrantes)
Le problème du choix de la partition
Question centrale: Parmi les \(n\) partitions possibles, laquelle choisir ?
Critères pratiques :
Interprétabilité scientifique ou métier.
Pertinence opérationnelle.
Nombre de groupes \(K\) déterminé à l’avance.
Critère de décomposition de l’inertie
\[I_{\text{tot}} = \frac{1}{n}\sum_{i=1}^{n} d^2(X_i, G)\]
\[I_{\text{tot}} = I_{\text{intra-groupe}} + I_{\text{inter-groupe}}\]
Objectif : Maximiser \(I_{\text{inter-groupe}}\) (séparation des groupes).
Critère de décomposition de l’inertie
Inertie inter-groupe (séparation) :
\[I_{\text{inter-groupe}} = \frac{1}{n}\sum_{k=1}^{K} n_k d^2(G_k, G)\]
Inertie intra-groupe (compacité) :
\[I_{\text{intra-groupe}} = \frac{1}{n}\sum_{k=1}^{K} \sum_{i \in C_k} d^2(X_i, G_k)\]
Principe : Groupes compacts \(\Rightarrow\) faible inertie intra-groupe.
Critères dérivés de l’inertie
Pseudo-\(R^2\) (Proportion d’inertie expliquée par la partition) :
\[\text{pseudo-}R^2 = \frac{I_{\text{inter-groupe}}}{I_{\text{tot}}}\]
Statistique Calinski-Harabasz (CH) (Équilibre entre compacité et séparation) :
\[\text{CH} = \frac{I_{\text{inter-groupe}} / (K-1)}{I_{\text{intra-groupe}} / (n-K)}\]
Critères basés sur la distance
Indice de Dunn :
\[D = \frac{\text{Distance minimale entre 2 groupes}}{\text{Distance maximale dans un groupe}}\]
Objectif : Maximiser \(D\)
Groupes denses (faible distance interne).
Groupes bien séparés (grande distance externe).
Critères basés sur la distance
Indice de silhouette :
\[S(X_i) = \frac{b_i - a_i}{\max(b_i, a_i)}\] où :
\(a_i\) : distance moyenne aux observations du même groupe
\(b_i\) : distance moyenne au groupe le plus proche
Critères basés sur la distance
Interprétation de l’indice de Silhouette :
\(S(X_i) \approx 1\) : Bien classée.
\(S(X_i) \approx 0\) : À la frontière.
\(S(X_i) \approx -1\) : Mal classée.
Silhouette moyenne : Indicateur de cohérence globale de la partition.
Avantage : Intuitive et facilement interprétable.
Usage : Souvent utilisée pour choisir le nombre optimal de groupes.
Recommandations pratiques
Croiser les approches :
Connaissance métier
Visualisation (dendrogramme)
Critères statistiques multiples
Aucun critère n’est parfait :
Complémentarité des indicateurs
Décision éclairée et contextualisée
Validation :
Interprétabilité des groupes obtenus
Stabilité des résultats
Exemple
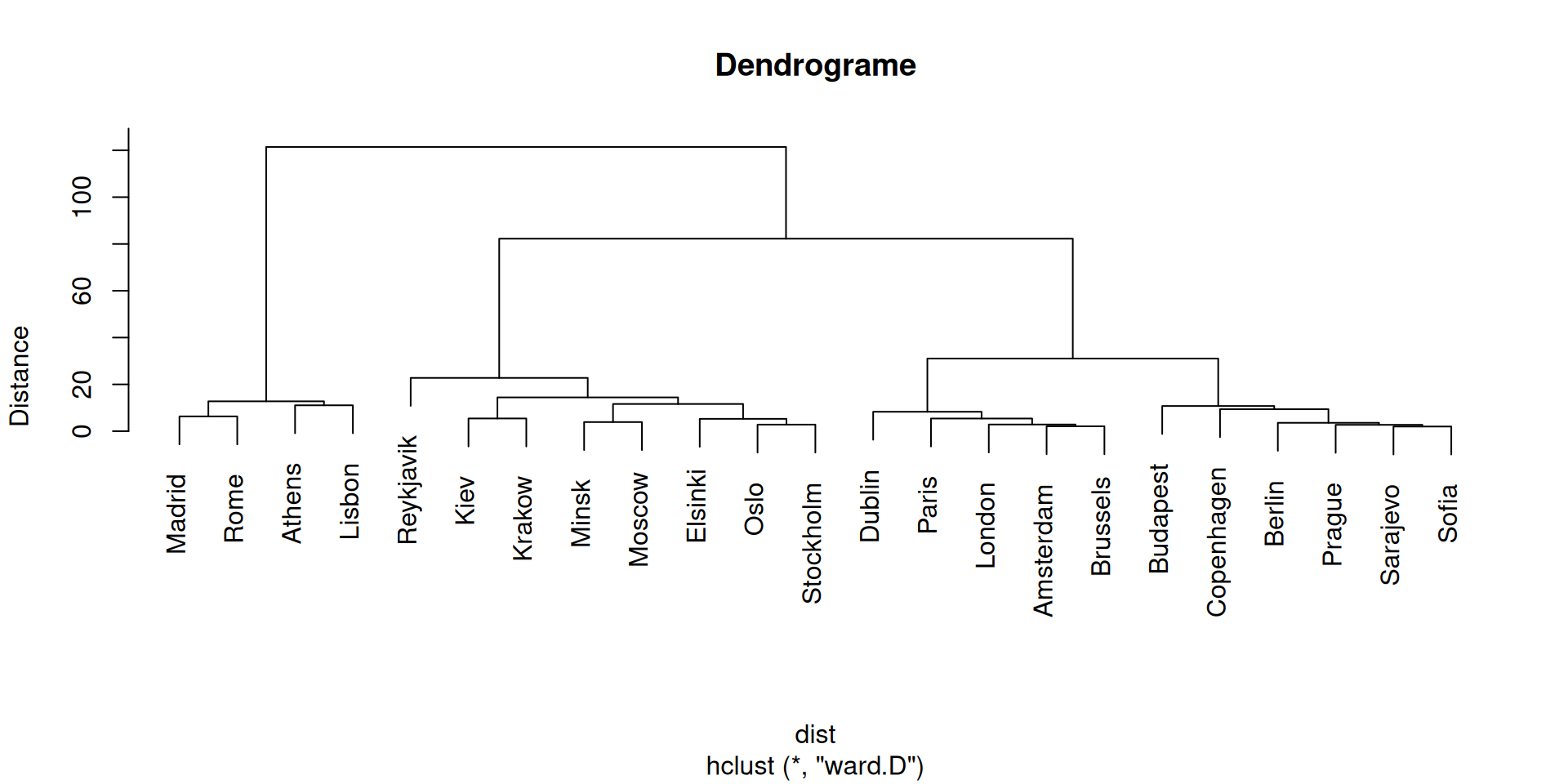
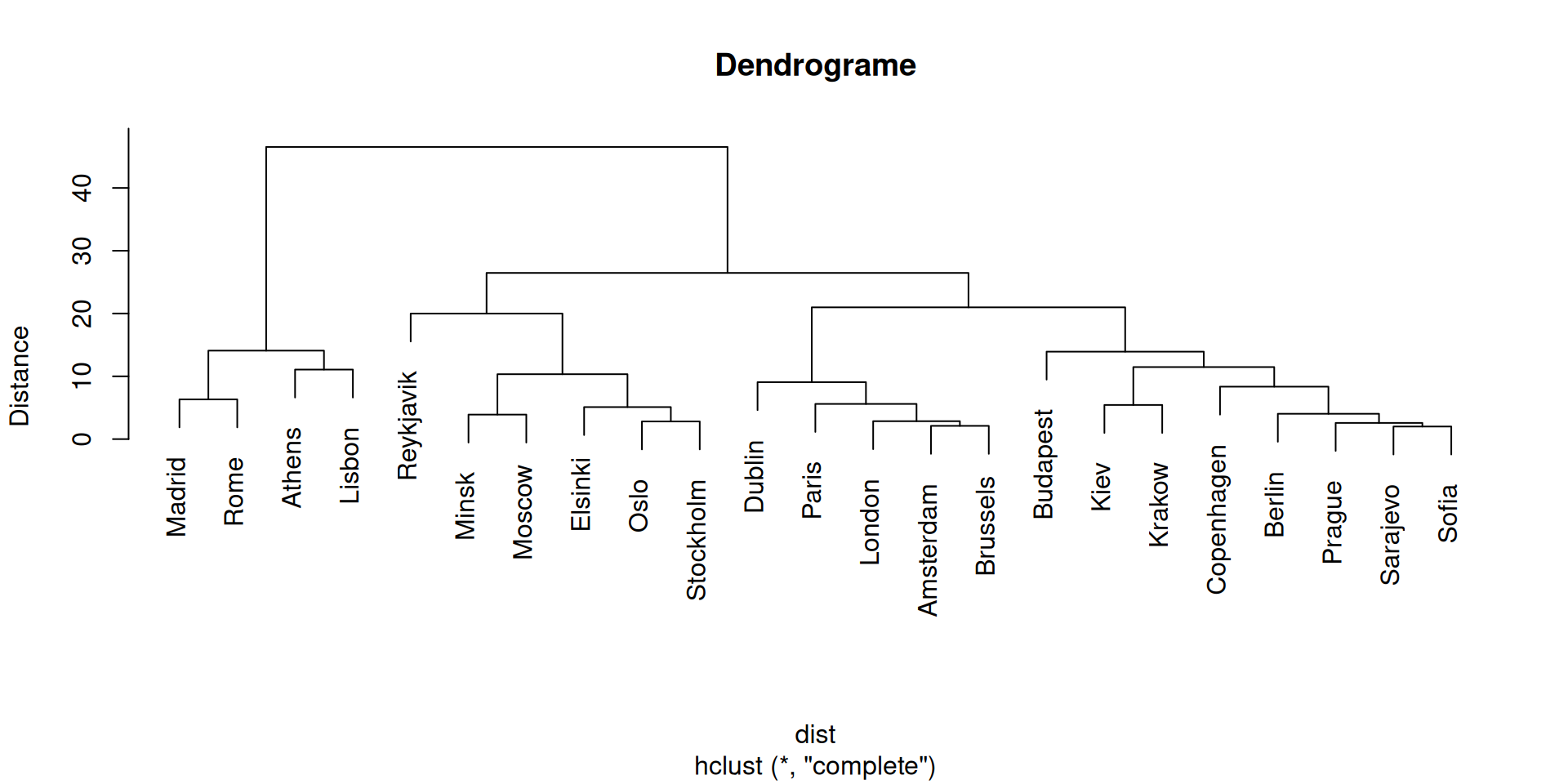
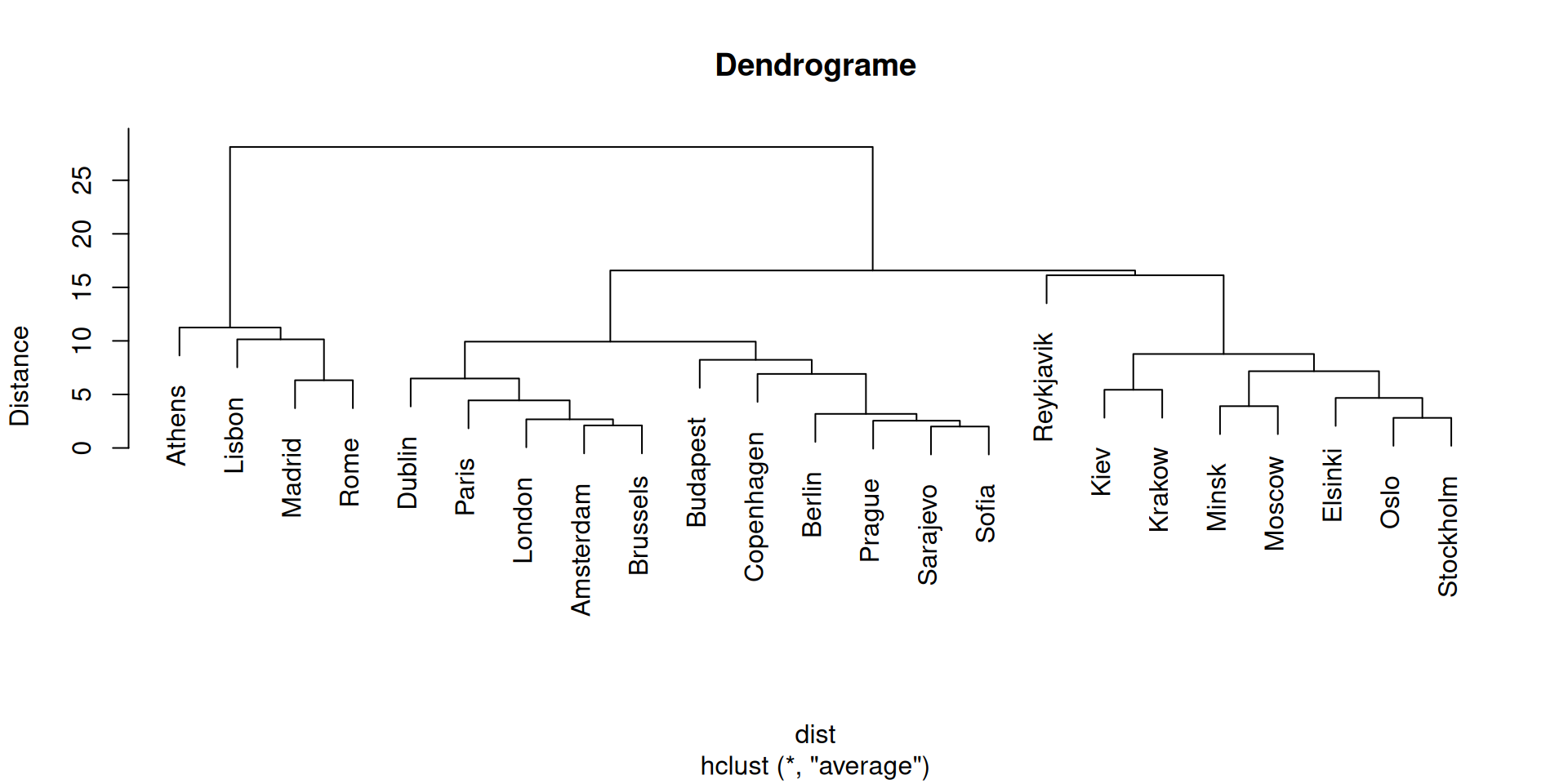
Récapitulatif
Classification hiérarchique :
Exploration complète de la hiérarchie de groupes
Choix de méthode de distance crucial
Méthodes populaires : Ward (sous hypothèses gaussiennes) / Average linkage (bon compromis)
Choix du nombre de groupes : Combinaison de critères pratiques et statistiques
Prochaine étape → \(k\)-moyennes