Non-supervisée
\(k\)-moyennes
28 nov. 2025

Plan
Généralités
\(k\)-moyennes
Extension
Exemple
Fonction de classification
\[C: \{1, \ldots, n\} \to \{1, \ldots, K\}\] Associe à chaque observation \(i\) une étiquette de groupe \(C(i)\).
Fonction de coût
\[W(C) = \sum_{k=1}^{K} \sum_{i: C(i)=k} \sum_{j: C(j)=k} d(X_i, X_j)\] où \(d(X_i, X_j)\) mesure la dissimilarité entre observations.
Objectif → Minimiser \(W(C)\) (cohésion intra-groupe).
Complexité du problème
Problème d’optimisation combinatoire :
Solution pratique : Algorithmes gloutons
Exploration d’un sous-ensemble restreint.
Amélioration itérative progressive.
Convergence vers un minimum local.
Hypothèses pour les \(k\)-moyennes
Variables numériques, souvent centrées-réduites.
Nombre de groupes \(K\) fixé à l’avance.
Algorithme des \(k\)-moyennes
Objectif → Regrouper \(n\) observations en \(K\) groupes homogènes.
Mesure de dissimilarité → généralement distance euclidienne.
Algorithme détaillé
Choix de \(K\) : Nombre de groupes fixé à l’avance.
Initialisation : Partition aléatoire ou centres initiaux aléatoires.
Calcul des centroïdes : \[\mu_k = \frac{1}{N_k} \sum_{i: C(i)=k} X_i\]
Réaffectation : Chaque observation au centre le plus proche.
Itération : Répéter 3-4 jusqu’à stabilisation.
Convergence
Garantie de convergence en nombre fini d’itérations.
Chaque étape réduit l’inertie intra-groupe (somme des distances observations / centroïdes).
⚠️ Limitation importante → Convergence vers un minimum local, pas nécessairement global.
Limites des \(k\)-moyennes
Sensibilité à l’initialisation
Choix de \(K\) à l’avance
Coût computationnel
Limites
Sensibilité aux valeurs extrêmes
La moyenne est influencée par les observations atypiques.
Les centroïdes sont faussés.
Les regroupements sont incohérents.
Conséquence → Nécessité de prétraiter les données (détection d’outliers).
\(k\)-médoïdes
Différence avec \(k\)-means → Utilise des observations réelles comme représentants (pas des moyennes).
Médoïde → Observation qui minimise la somme des distances aux autres observations du même groupe.
Avantage conceptuel → Représentants concrets et interprétables
Avantages des \(k\)-médoïdes
Robustesse aux valeurs extrêmes
Flexibilité
Inconvénients des \(k\)-médoïdes
Problèmes partagés avec \(k\)-moyennes :
Coût computationnel plus élevé :
Calculs plus complexes pour identifier médoïdes
Particulièrement avec distances non-euclidiennes
Problématique pour grands jeux de données
Comparaison des méthodes
| Représentants |
Centroïdes (moyennes) |
Observations réelles |
| Robustesse |
Sensible aux outliers |
Plus robuste |
| Types de variables |
Numériques |
Numériques + ordinales |
| Coût computationnel |
Modéré |
Plus élevé |
| Interprétabilité |
Abstraite |
Concrète |
Critères de choix de \(K\)
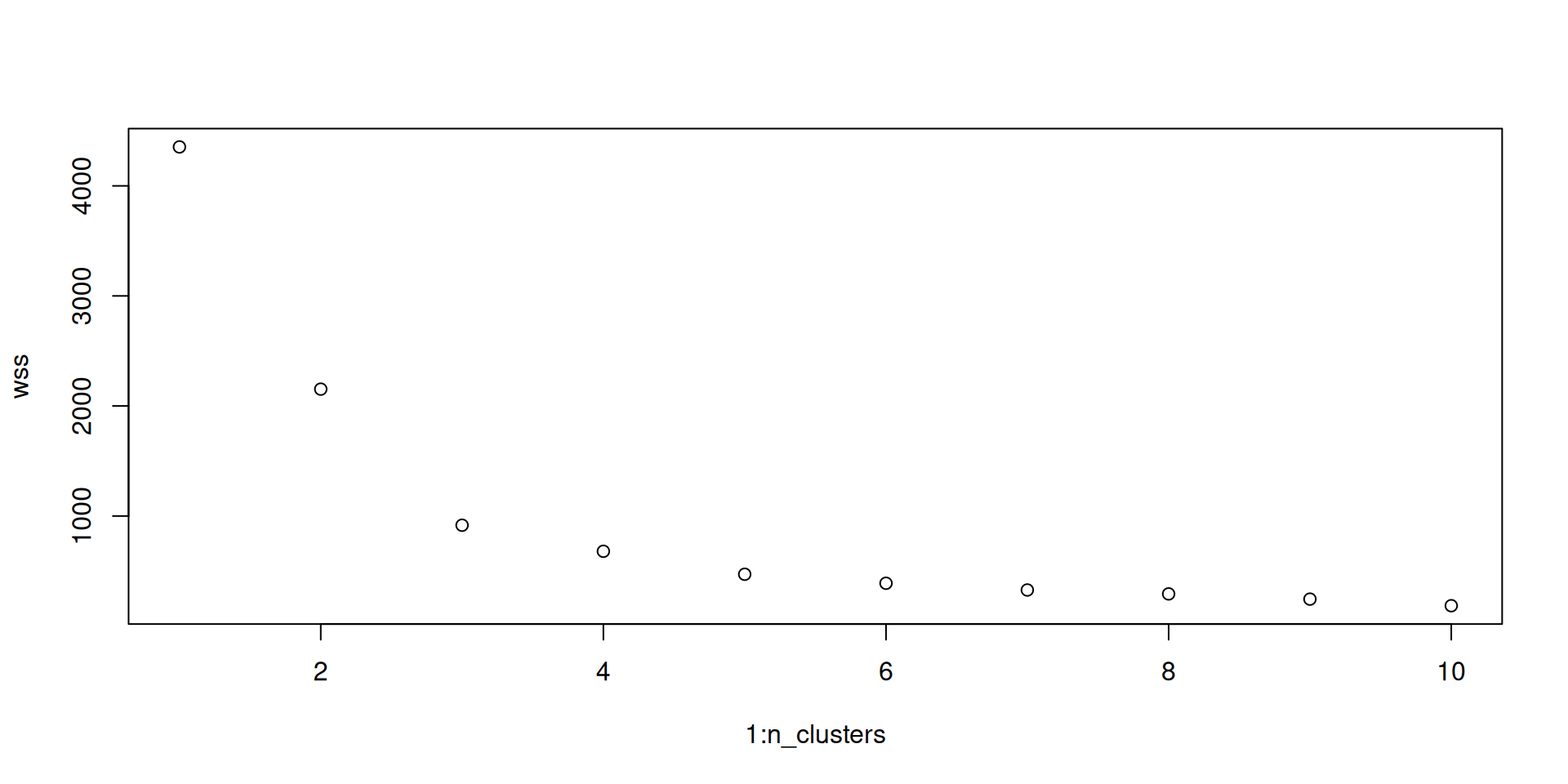
Méthode du coude (Elbow method)
Coefficient de silhouette
Critères d’information
Exemple
library(tidyverse)
temp <- read.table('../include/data/unsupervised/temperature.csv', header = TRUE, sep = ";", dec = '.', row.names = 1)
df <- temp[1:23, 1:12]
city <- row.names(temp[1:23,])
model <- kmeans(df, centers = 3)
K-means clustering with 3 clusters of sizes 11, 8, 4
Cluster means:
January February March April May June July August
1 1.090909 1.854545 5.009091 8.754545 13.23636 16.29091 18.30909 17.95455
2 -4.962500 -4.275000 -0.762500 5.075000 11.13750 15.00000 16.98750 15.75000
3 7.925000 8.950000 11.100000 13.950000 17.65000 21.60000 24.50000 24.37500
September October November December
1 14.800 10.50909 5.572727 2.609091
2 11.325 6.11250 0.850000 -2.762500
3 21.225 16.75000 12.175000 8.950000
Clustering vector:
Amsterdam Athens Berlin Brussels Budapest Copenhagen
1 3 1 1 1 1
Dublin Elsinki Kiev Krakow Lisbon London
1 2 2 2 3 1
Madrid Minsk Moscow Oslo Paris Prague
3 2 2 2 1 1
Reykjavik Rome Sarajevo Sofia Stockholm
2 3 1 1 2
Within cluster sum of squares by cluster:
[1] 364.2236 388.8175 163.0600
(between_SS / total_SS = 79.0 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"
n_clusters <- 10
wss <- numeric(n_clusters)
for (i in 1:n_clusters) {
model <- kmeans(df, centers = i)
wss[i] <- model$tot.withinss
}
plot(1:n_clusters, wss)
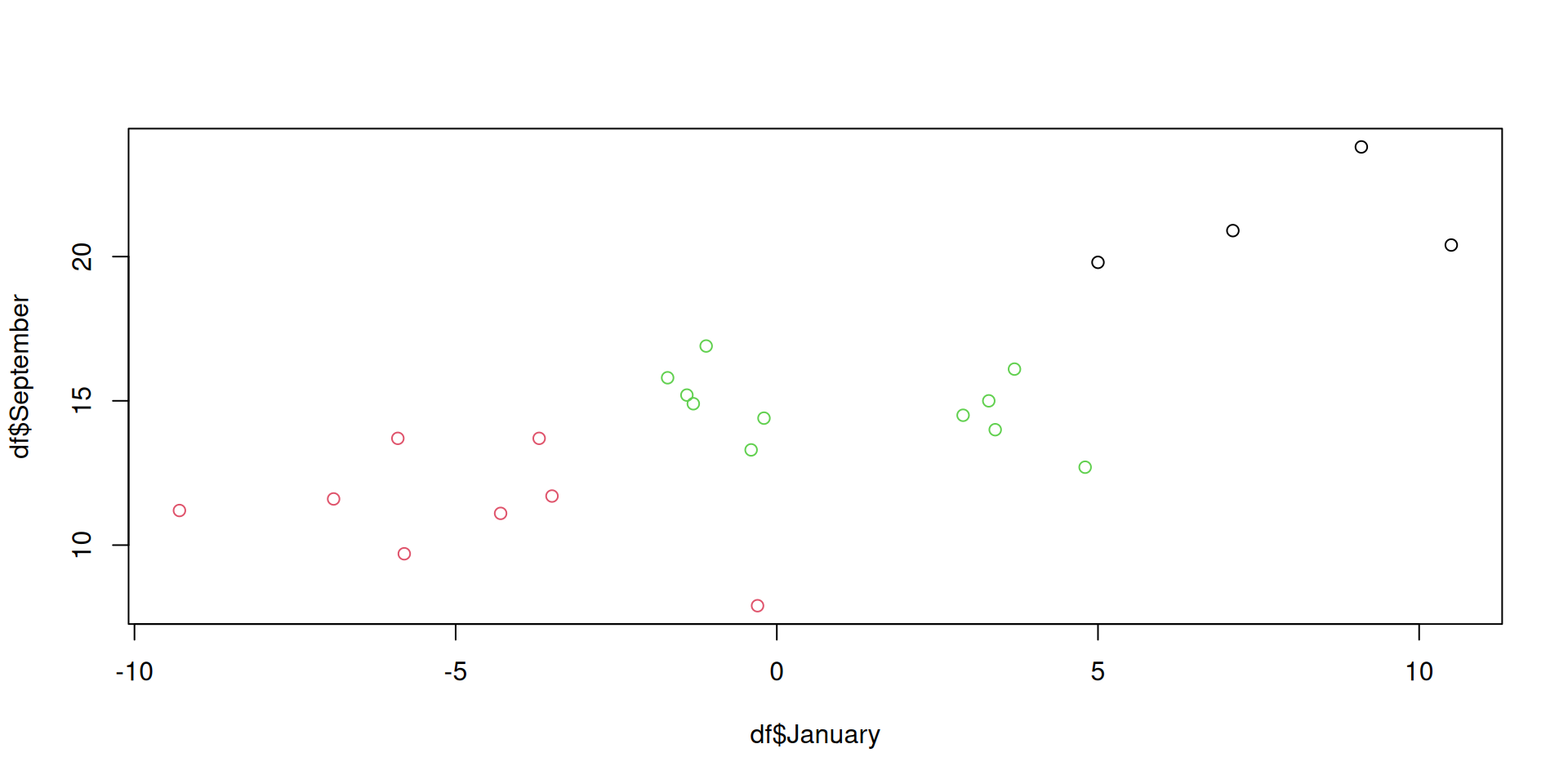
model <- kmeans(df, centers = 3)
plot(df$January, df$September, col = model$cluster)
Récapitulatif
\(k\)-moyennes : Méthode classique, efficace mais limitations.
\(k\)-médoïdes : Alternative robuste mais a un coût plus élevé.
Choix du nombre de groupes : Combinaison de critères pratiques et statistiques