Cette section est basée sur James et al. (2021), chapitre 5.
Évaluer la performance d’un modèle prédictif
Dans la section précédente, nous avons introduit des outils pour mesurer la qualité d’un estimateur : l’erreur quadratique moyenne (MSE) pour les variables quantitatives et le taux d’erreur (ER) pour les variables qualitatives. Ces mesures comparent les valeurs prédites \(\widehat{Y} = \widehat{f}(X)\) aux valeurs observées \(Y\). Cependant, si l’on calcule ces erreurs uniquement à partir des données qui ont servi à entraîner le modèle, on risque de sous-estimer la véritable erreur de prédiction. Pourquoi ? Parce que l’estimateur \(\widehat{f}\) a été ajusté pour minimiser l’erreur sur ces mêmes données. Il s’y adapte donc bien, et généralement, trop bien ! Cela peut conduire à l’illlusion que notre modèle est performant. En effet, un modèle très flexible peut avoir une erreur faible sur les données d’entraînement simplement parce qu’il capture le bruit plutôt que le signal. Mais si le modèle s’adapte trop aux données d’entraînement, il risque de mal généraliser à de nouvelles données, i.e. des données qu’il n’a jamais vues. Ce phénomène s’appelle le sur-ajustement (overfitting).
AstuceRemarque: Sur-ajustement et sous-ajustement
Un modèle trop flexible peut s’adapter parfaitement aux données d’entraînement, y compris au bruit aléatoire. Il aura une erreur faible sur ces données mais une erreur élevée sur de nouvelles observations. On dira qu’il y a sur-ajustement (overfitting) du modèle. À l’inverse, un modèle trop rigide (par exemple, une droite constante) ne pourra pas capturer la structure des données, même sur l’ensemble d’entraînement. On dira qu’il y a sous-ajustement (underfitting) du modèle.
L’objectif est de trouver le bon compromis entre flexibilité et capacité de généralisation.
Pour évaluer objectivement un modèle, l’idéal serait de le tester sur des données complètement indépendantes de celles utilisé pour l’apprentissage. On distingue donc deux ensembles : un jeu d’entraînement, utilisé pour ajuster le modèle et un jeu de test, utilisé pour évaluer la performance prédictive du modèle. En practique, nous n’avons généralement pas accès à un jeu de test pour faire cette évaluation. Dans cette section, nous allons deux approches permettant de contourner ce problème.
Jeu de données de validation
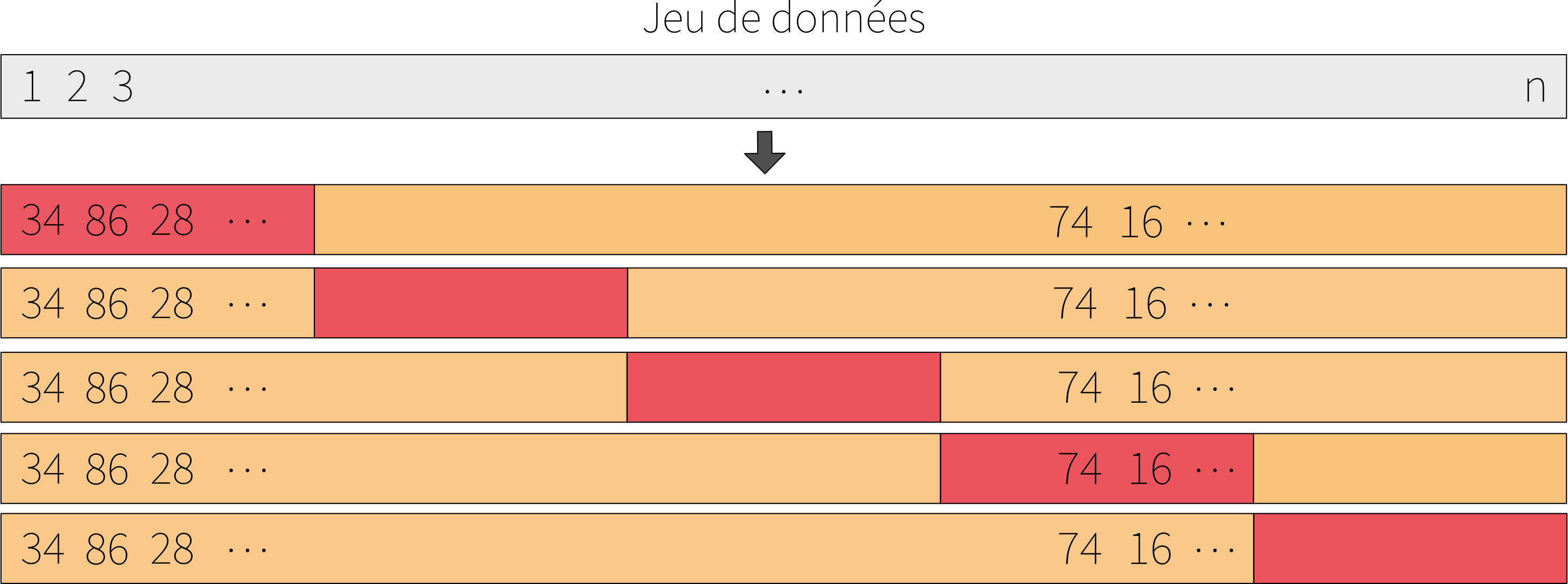
Quand on ne dispose que d’un seul jeu de données, une solution simple consiste à le diviser aléatoirement en deux sous-ensembles : un jeu d’entraînement pour ajuster le modèle et un jeu de validation pour estimer l’erreur de prédiction. On parle alors d’approche par jeu de validation. La Figure 1 présente un schéma de cette approche et la Figure 2 présente plusieurs combinaisons de jeux de données d’entraînement et de validation, ainsi que les MSE associées.
Figure 1: Schéma de l’approche par jeu de validation.
Code
# Load packageslibrary(tidyverse)library(dplyr)# Set seed for reproducibilityset.seed(42)# Function definitionf <-function(x) {4* x * (1- x) *log(x) +2}generate_splits <-function(data, train_prop =0.7, K =10) { rows <-list()for (k in1:K) { idx_train <-sample(nrow(data), size =floor(train_prop *nrow(data))) train <- data[idx_train, ] validation <- data[-idx_train, ] train_tbl <-tibble(split = k,set ="train",x = train$x,y = train$y ) validation_tbl <-tibble(split = k,set ="validation",x = validation$x,y = validation$y ) rows[[k]] <-bind_rows(train_tbl, validation_tbl) }bind_rows(rows)}# Generate N data points in the interval (0, 1]N <-200spans <-seq(0.1, 1, by =0.05) # LOESS smoothing parametersx_all <-runif(N, min =0.01, max =1) # avoid 0 due to log(x)y_all <-f(x_all) +rnorm(N, mean =0, sd =0.1) # add Gaussian noise# Put everything in a data.framedata <-data.frame(x = x_all, y = y_all)# Generate 10 training/validation splitssplits <-generate_splits(data, train_prop =0.7, K =10)write.csv(splits, './splits.csv')# Fit a model with different smoothing parameters on each splitsplits_number <-unique(splits$split)results <-list()for (n_split in splits_number) { df_split <- splits |> dplyr::filter(split == n_split) train <- df_split |> dplyr::filter(set =='train') |> dplyr::select(x, y) validation <- df_split |> dplyr::filter(set =='validation') |> dplyr::select(x, y) results_splits <-list()for (s in spans) {# Fit loess model with span = s on train and predict on validation model <-loess(y ~ x, data = train, span = s, degree =2) pred <-predict(model, newdata = validation$x)# For each point in x_grid, compute bias², variance, MSE bias2 <-mean((pred - validation$y)^2, na.rm =TRUE) var_pred <-var(pred, na.rm =TRUE) mse <- bias2 + var_pred results_splits[[as.character(s)]] <-data.frame(split = n_split,span = s,MSE = mse ) } results_splits_df <-bind_rows(results_splits) results[[as.character(n_split)]] <- results_splits_df}results <- results |>bind_rows()write.csv(results, './splits_mse.csv')
Code
data =FileAttachment("../../include/data/model-evaluation/splits.csv").csv({ typed:true })data_mse =FileAttachment("../../include/data/model-evaluation/splits_mse.csv").csv({ typed:true })viewof split = Inputs.range( [1,10], {value:1,step:1,label:"Autre jeu de validation"})filtered = data.filter(function(df) {return df.split== split;})current_mse = data_mse.filter(function(df) {return df.split== split;})
Figure 2: Illustration de l’approche par jeu de données de validation.
AstuceComment choisir la taille des sous-ensembles ?
En général :
Si l’on dispose d’un grand nombre d’observations (disons plusieurs milliers), on peut faire une division \(50-50\).
Si l’on dispose de moins d’observations, on préférera garder plus d’observations pour l’entraînement. On peut, par exemple, faire une division \(70-30\) ou \(80-20\).
Cependant, il n’existe pas de règle universelle. Le bon choix dépend du contexte, de la complexité du modèle et de la quantité de données disponibles.
La méthode a cependant deux inconvénients. Le premier est que l’estimation de l’erreur est instable. En effet, la valeur de l’erreur de prédiction dépend des observations qui sont dans le jeu de validation. Un autre jeu de validation peut donner un résultat différent. Le deuxième est qu’il y a moins de données pour ajuster le modèle. Comme une partie des données est réservée à la validation, le modèle est appris sur un ensemble plus petit, et cela peut donc surestimer son erreur réelle par rapport à s’il avait été appris sur l’ensemble de données complet.
Validation croisée
Pour contourner les limites de l’approche précédente, on utilise souvent la validation croisée (cross-validation). Cette méthode est plus robuste et plus stable. Le principe est de répéter l’approche par jeu de validation plusieurs fois sur différents sous-ensembles du jeu de données.
L’approche consiste à découper aléatoirement l’ensemble des observations en \(K\) sous-ensembles de taille équivalentes (appelés folds). Le premier fold est utilisé comme jeu de données de validation et le modèle est ajusté sur les \(K - 1\)folds restant. L’erreur de prédiction est calculé sur le premier fold. Cette procédure est répèté \(K\) fois; à chaque fois, un différent fold est utilisé comme jeu de données de validation. À la fin, on a donc \(K\) valeurs pour l’erreur de prédiction. On calcule enfin la moyenne des \(K\) valeurs de prédiction. La Figure 3 présente un schéma de cette approche.
Figure 3: Schéma de l’approche par validation croisée
AstuceComment choisir le nombre de sous-ensembles \(K\) ?
Le choix du nombre de sous-ensembles \(K\) a un impact sur la qualité de l’estimation de l’erreur de prédiction, ainsi que sur le coût computationnel de la procédure. En pratique, on utilise souvent \(K = 5\) ou \(K = 10\). Ce choix repose sur un compromis entre la précision de l’estimation de l’erreur et le temps de calcul nécessaire. En effet, pour chaque valeur de \(K\), le modèle est ajusté \(K\) fois. Par conséquent, plus \(K\) est grand, plus le coût computationnel augmente.
Dans le cas limite où \(K = n\), i.e. \(K\) est égal au nombre d’observations dans le jeu de données, on parle de validation croisée leave-one-out (LOOCV). Dans ce cas, chaque observation sert une fois de validation et le modèle est entraîner sur les \(n - 1\) autres observations.
Ce choix de \(K = n\) minimise le biais dans l’estimation de l’erreur de prédiction, car à chaque itération, le modèle est ajusté sur presque toutes les observations du jeu de données. Cependant, cela se fait au prix d’une forte variance. En effet, comme les ensembles d’entraînement sont presque identiques, les erreurs de prédiction sont très corrélées entre elles, ce qui rend l’estimation globale de l’erreur instable.
Inversement, des valeurs plus faibles de \(K\) introduisent un léger biais dans l’estimation de l’erreur (car les modèles sont ajustés sur des ensembles contenant moins d’observations), mais réduisent la variance de cette estimation. Ce compromis biais/variance, couplé à une réduction significative du temps de calcul, explique pourquo \(K = 5\) ou \(K = 10\) sont des choix standards en pratique.
Pour finir, la validation croisée est une méthode générale qui peut être appliquée avec la plupart des modèles.
Les références
James, Gareth, Daniela Witten, Trevor Hastie, et Robert Tibshirani. 2021. An Introduction to Statistical Learning: With Applications in R. Springer Texts in Statistics. New York, NY: Springer US. https://doi.org/10.1007/978-1-0716-1418-1.